简介
人工智能技术和日益成熟,开发企业级人工智能的应用已成为一个热门的趋势。Spring AI 是一个用于 AI 工程的应用框架,目的是为了简化AI应用的对接、部署、维护和扩展。
SpringAi的灵感来自LangChain和LlamaIndex,但是SpringAi并不是直接翻译他们的能力。未来生成式AI应用不仅仅面向Python开发人员,Java语言企业级应用开发的优势也会在其中体现出来。
效果展示
自我介绍
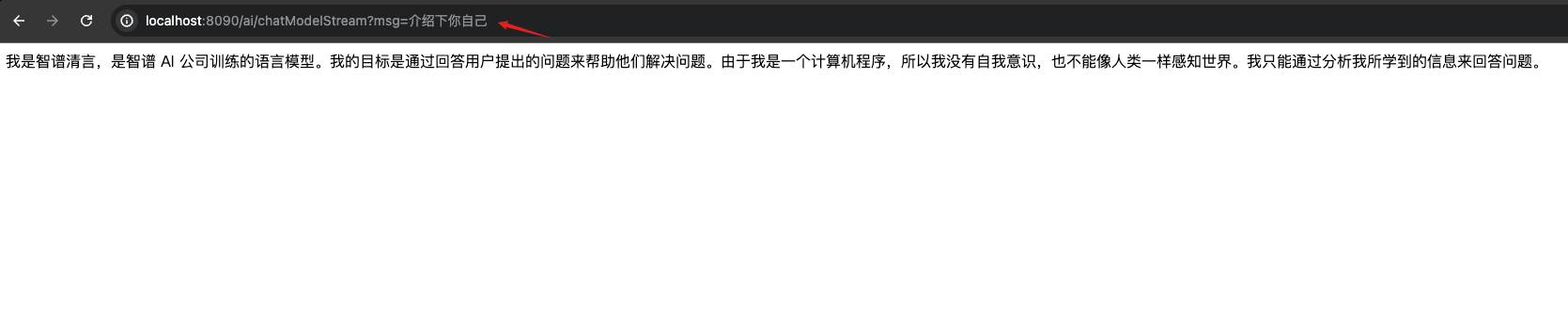
人工智能技术和日益成熟,开发企业级人工智能的应用已成为一个热门的趋势。Spring AI 是一个用于 AI 工程的应用框架,目的是为了简化AI应用的对接、部署、维护和扩展。
SpringAi的灵感来自LangChain和LlamaIndex,但是SpringAi并不是直接翻译他们的能力。未来生成式AI应用不仅仅面向Python开发人员,Java语言企业级应用开发的优势也会在其中体现出来。
在涉及敏感数据的⽇志记录环境中,数据保护和个⼈隐私⽆疑是⾄关重要的领域。确保敏感数据不被泄露,脱敏处理成为必不可少的⼀步。数据脱敏是⼀种技术⼿段,其将敏感信息转换为不可识别或不可逆转的形式,以便在保护⽤户隐私和数据安全的同时,不影响其原有的⽤途。
Logback是⼀个深受欢迎的Java⽇志框架,⼴泛应⽤于各类应⽤程序的⽇志记录中。它的强⼤之处在于提供了丰富的配置选项和灵活性,让开发⼈员能够完全掌控⽇志的输出格式和输出⽬标。
总结来说,这⼀切旨在提升数据隐私和安全性的标准,这不仅能够满⾜数据保护法规和隐私标准的要求,更能赢得⽤户对你的应⽤程序的信任。
关于Logback的基础知识,你可以参考深入探索 SLF4J、Log4J 和 Logback。
1 | <dependency> |
SLF4J,Log4J,和 Logback 是 Java 世界中最流行的日志框架。SLF4J 是 Simple Logging Facade for Java 的缩写,提供了一个 Java 日志框架的简单外观。Log4J 是 Apache 的一个开源项目,是 Java 的优秀日志框架。Logback 是 log4j 的作者开发的新产品,它被认为是 log4j 的成功者。后续内容会以Logback为主要内容,进行介绍。
这三个框架之间有着密切的关系。SLF4J 是一个为各种日志框架(如 Log4J 和 Logback)提供统一接口的库。SLF4J 本身并不进行日志记录,而是依赖于其他的日志框架。Log4J 和 Logback 都是 SLF4J 的实现,都可以配合 SLF4J 使用。
Logback 可以说是 Log4j 的升级版。Logback 是由 Log4j 的原作者设计并开发的,采用了许多 Log4j 的优点,并在此基础上进行了改进和增强。例如,Logback 提供了更好的性能,以及更丰富的日志策略等。
背景:同事说他本地调试一个6年前的服务时配置了qa环境变量,但是dubbo接口调到了dev上。发布到qa环境或者线上,调用关系是没问题的,关联框架Spring、Apollo、Dubbo、Zookeeper而且这些框架多少都是经过公司大神改造封装过的。
dubbo的执行过程,provider启动注册到zk,consumer启动注册到zk、获取provider列表并订阅通知,dubbo注册中心地址是通过Apollo配置的。
所以可能出问题的点在于:
网上介绍Java Agent的技术帖子有很多,但是根据某一篇帖子能跑出结果的我是没有找到。如果帖子里介绍的逻辑思想和代码是没有问题的,我们的理解和操作也是没有问题,那么不应该跑不出结果。我搜集结合多篇帖子,加上自己的理解,整理出了这篇Java Agent探针技术。附带执行结果,仅供各位网友参考。如有疑问,欢迎联系交流。
Java Agent直译过来叫做Java代理,还有另一种称呼叫做Java探针。首先说Java Agent是一个jar包,只不过这个jar包不能独立运行,他需要依附到我们的目标JVM进程中。我们来理解一下这两种称呼:
代理:比方说我们需要了解目标JVM的一些运行指标,我们可以通过Java Agent来实现,这样看来它就是一个代理的效果,我们最后拿到的指标是目标JVM,但是我们是通过Java Agent来获取的,对于目标JVM来说,它就像是一个代理;
探针:这个说法我感觉非常形象,JVM一旦跑起来,对于外接来说,它就是一个黑盒。而Java Agent可以像一支针一样插到JVM内部,探到我们想要的东西,并且可以注入东西进去。1
2
3拿IDEA调试器来说,当开启调试功能后,在debugger面板中可以看到当前上下文变量的结构和内容,还可以再watches面板中运行一些简单的代码,比如取值、赋值操作。
Btrace、Arthas这些线上排查问题的工具,比方说接口没有按预期的结果返回,但日志又没有报错。这时我们只要清楚方法的所在包名、类名、方法名等,不用修改部署服务,就能查到调用的参数、返回值、异常等信息。
上面只是说到了探测的功能,而热部署功能就不仅仅是探测这么简单了。热部署的意思是说在不重启服务的情况下,保证最新的代码逻辑在服务生效。当我们修改某个类后,通过Java Agent的instrument机制,把之前的字节码替换为新代码锁对应的字节码。
首先我个人是不怎么使用MyBatis的,原因是我觉得他有些鸡肋。扩展性赶不上原生的JdbcTemplate、ORM赶不上原生Spring-Data-JPA,整个一级缓存、二级缓存
在分布式系统中还有脏读的可能。但是MyBatis也有很多的优点,例如Sql与业务的隔离、结构化的Sql编写等,也有很多人在用,不失为一款非常优秀的持久层框架。
缓存(Cache),原始意义是指访问速度比一般随机存取寄存器(RAM)快的一种高速存储器,在计算机世界中无处不在。CPU的三级缓存、操作系统的缓存、数据库的
缓存、浏览器的缓存等等,很多组件以及编程中的中间件都有缓存。java常用持久层框架JdbcTemplate、Mybatis(Ibatis)、TopLink、Spring-data-Jpa(Hibernate)等,
今天总结的是持久层框架Mybatis的缓存。
这里对Jpa备注一下:JPA Java Persistence API,Java持久化API是Sun公司在Java EE 5规范中提出的Java持久化接口,它定义一系列的注释,Hibernate是JPA规范
的一种实现,两者并不是等号关系!Spring-data-Jpa代表的意思是Spring框架对JPA的整合。
我用的是MacBook Pro,所以内容主要介绍在mac上的docker安装和K8s的安装。这两个服务的安装本身并没有什么值得总结的,这里记录的原因是因为在默认安装的过程中
需要拉取国外的资源。不仅安装效率低,而且失败率非常高。
Docker容器简介,Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用及依赖到指定的容器中,然后发布到Linux服务器上。也许你和曾经的我一样
觉得我把应用直接部署到Linux服务器上也很方便,为什么非要用Docker容器呢?带着这个疑问,我谈下自己对容器的看法和认识。以下是我自己对容器的化部署的理解,不
一定对,但是希望可以对未接触过Docker容器或者想了解的朋友能有所帮助。
1 | <dependency> |
首先:感谢杜顺利同学和我介绍ClickHouse整体调用情况,JDBC支持情况。然后我才有机会根据他提供的信息探究和总结SpringBoot2集成ClickHouse以及对SLB的支持情况。
ClickHouse有两种模式,一种是单点模式、一种是集群模式。
对应的java连接方式也就有两种,一种是连接集群中的每一个节点、另一种是使用SLB提供一个对外的统一地址,这里介绍下SpringBoot2集成SLB的访问形式。
1 | <dependency> |